MOVE Fellow Expert
Nov 2025 - Present, Freelance

LLM Agentic - Associate Researcher
Oct 2025 - Mar 2026, Contract/ Full-time
Finance Research Expert
Nov 2025 - Dec 2025, Freelance (Project-based)

Founder/ Corporate Finance Analyst
Sep 2023 - Present, Part-time
Quality Analyst - Internal QA Team
Feb 2026 - Present, Contract/ Freelance
Project Lead Quality
Aug 2025 - Oct 2025, Contract
Quality Analyst
Jan 2025 - Jun 2026, Contract/ Freelance
GenAI Associate - Red Teaming
Jun 2025 - Aug 2025, Contract
V-Star Internship
Sep 2024 - Nov 2024, Internship
Career History
Other Contract/Freelance Roles
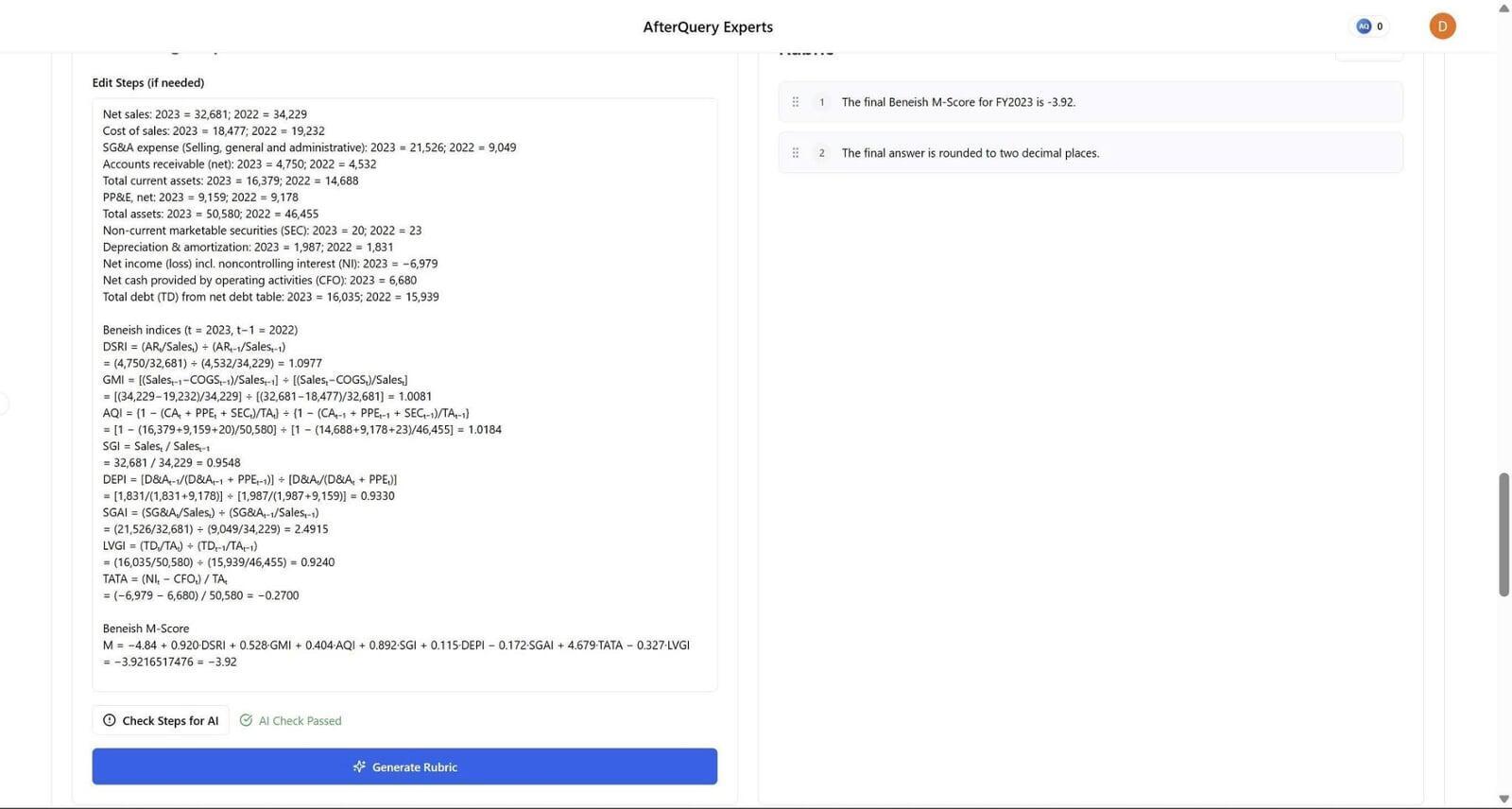
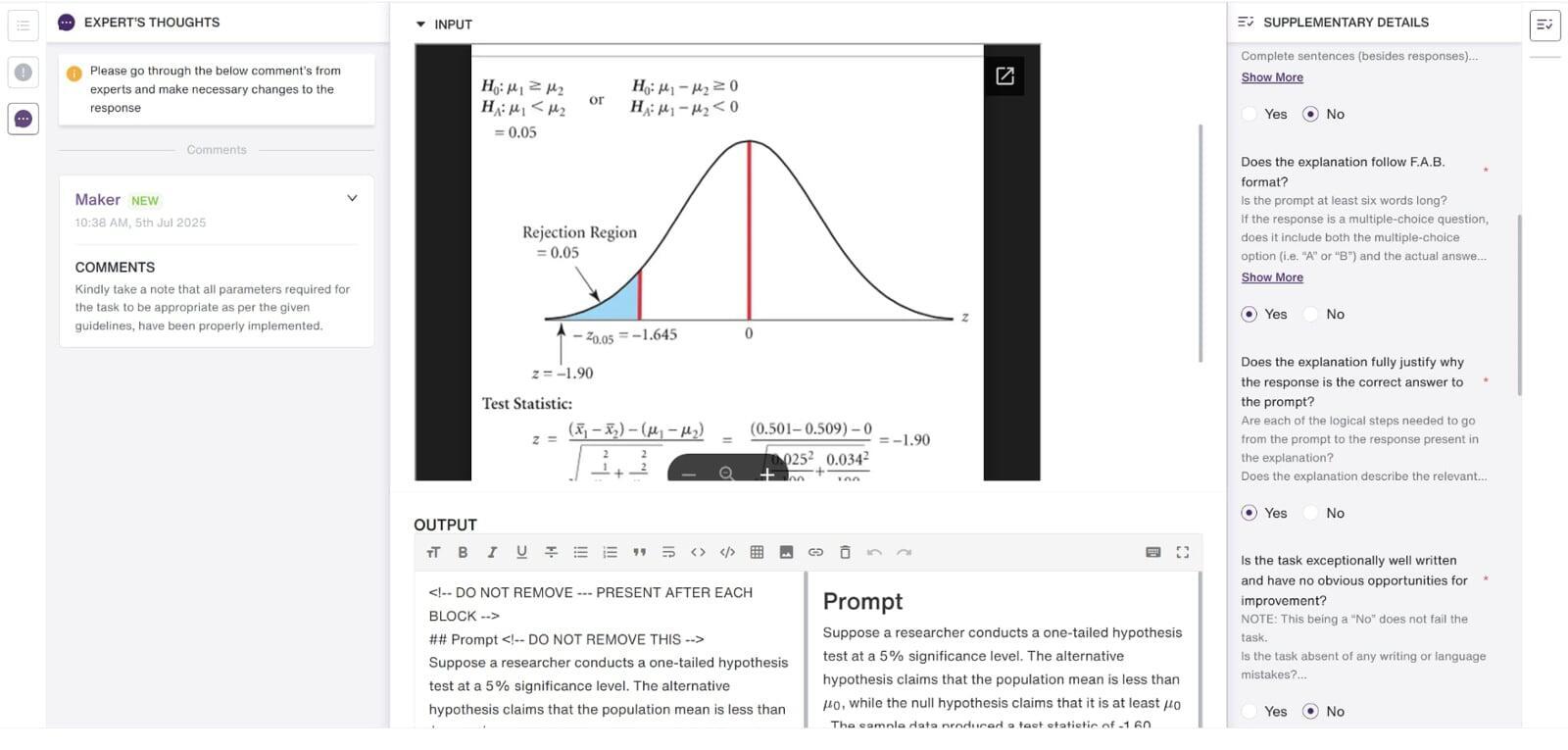
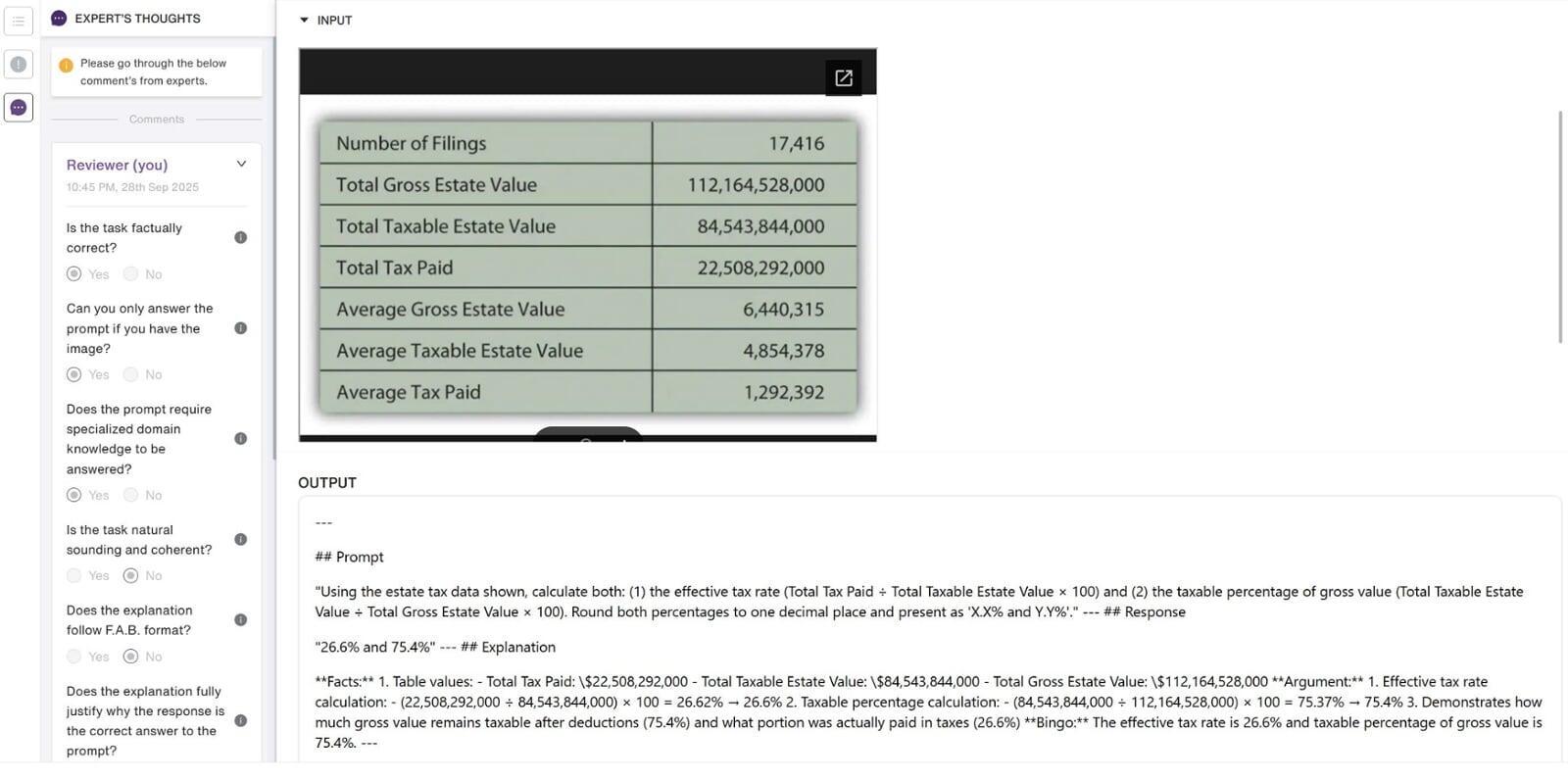
I design finance-focused questions to evaluate and stress-test AI reasoning models using real, verifiable data from U.S.-listed companies’ public disclosures (e.g., revenue, net income, and details from filings such as Form 10-K/10-Q and related financial statements). Beyond writing the question itself, I also draft a clear reasoning framework so the expected solution is logically sound and traceable to the source data, while still being challenging enough to reveal common model errors in accounting, valuation, market interpretation, and economics.
A key difficulty of the project is that the questions can’t be “generic” or easily solvable with surface-level finance knowledge. I often need to engineer subtle traps-such as timing mismatches (TTM vs. annual), segment vs. consolidated numbers, non-recurring items, share count definitions (basic vs. diluted), or classification differences (operating vs. non-operating)-to intentionally push models toward incorrect conclusions. At the same time, the question must remain fair and defensible, with inputs that come from real filings and a reasoning path that can be audited.
Another major challenge is balancing multiple models at once: I’m effectively testing around 10 finance reasoning models simultaneously, and I must ensure the question is difficult enough that at least 5 out of 10 models answer incorrectly. That means iterating on difficulty, wording, and numeric setup until the question reliably differentiates strong vs. weak reasoning-without becoming ambiguous or misleading. After submission through the platform, my work goes through quality review, and I respond to reviewer feedback by making precise revisions (tightening assumptions, clarifying constraints, or improving the reasoning steps) so the final approved questions meet both accuracy and evaluation objectives.
Below are images of some in-depth finance analyses that I worked on during the project:
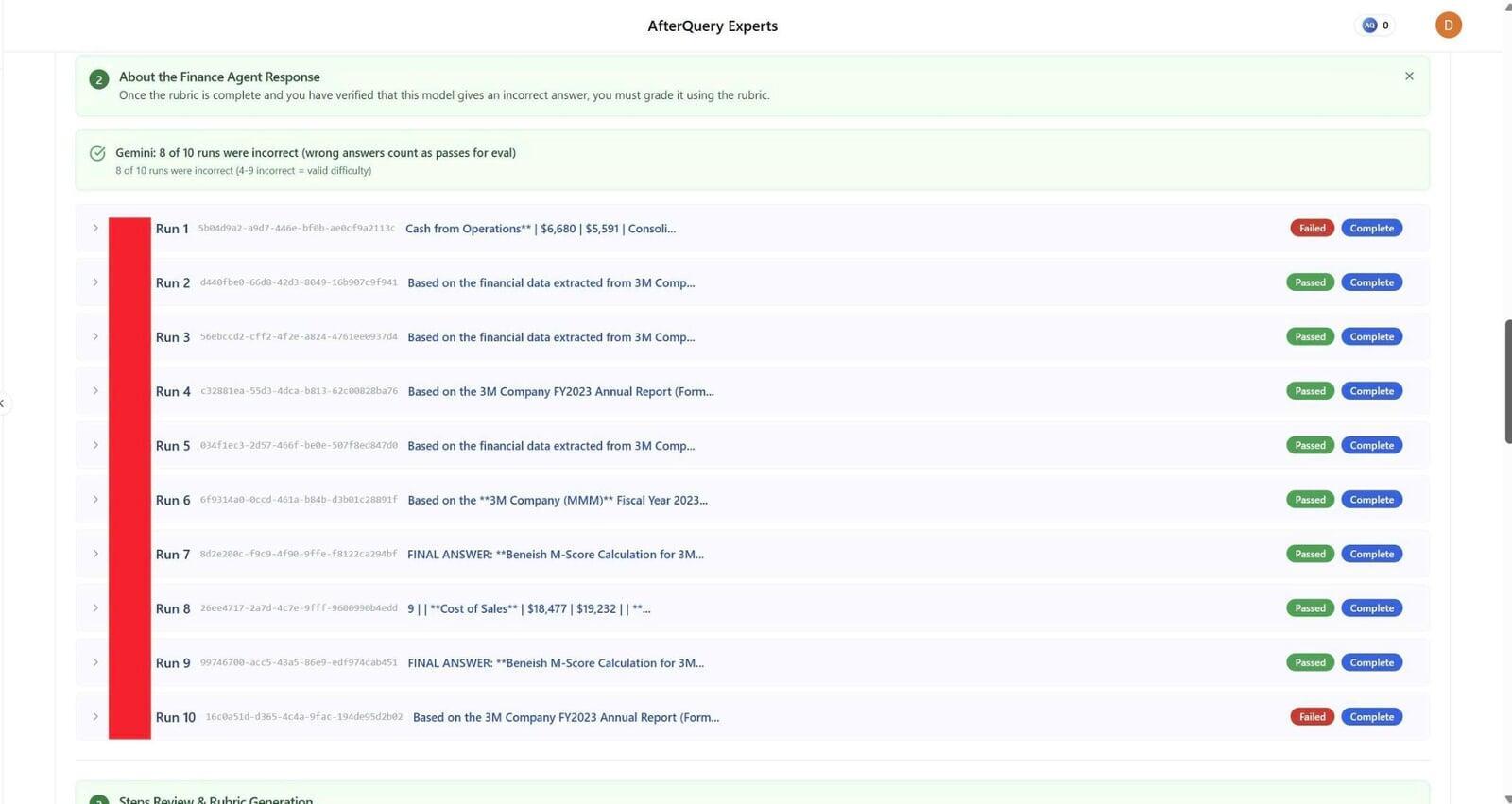
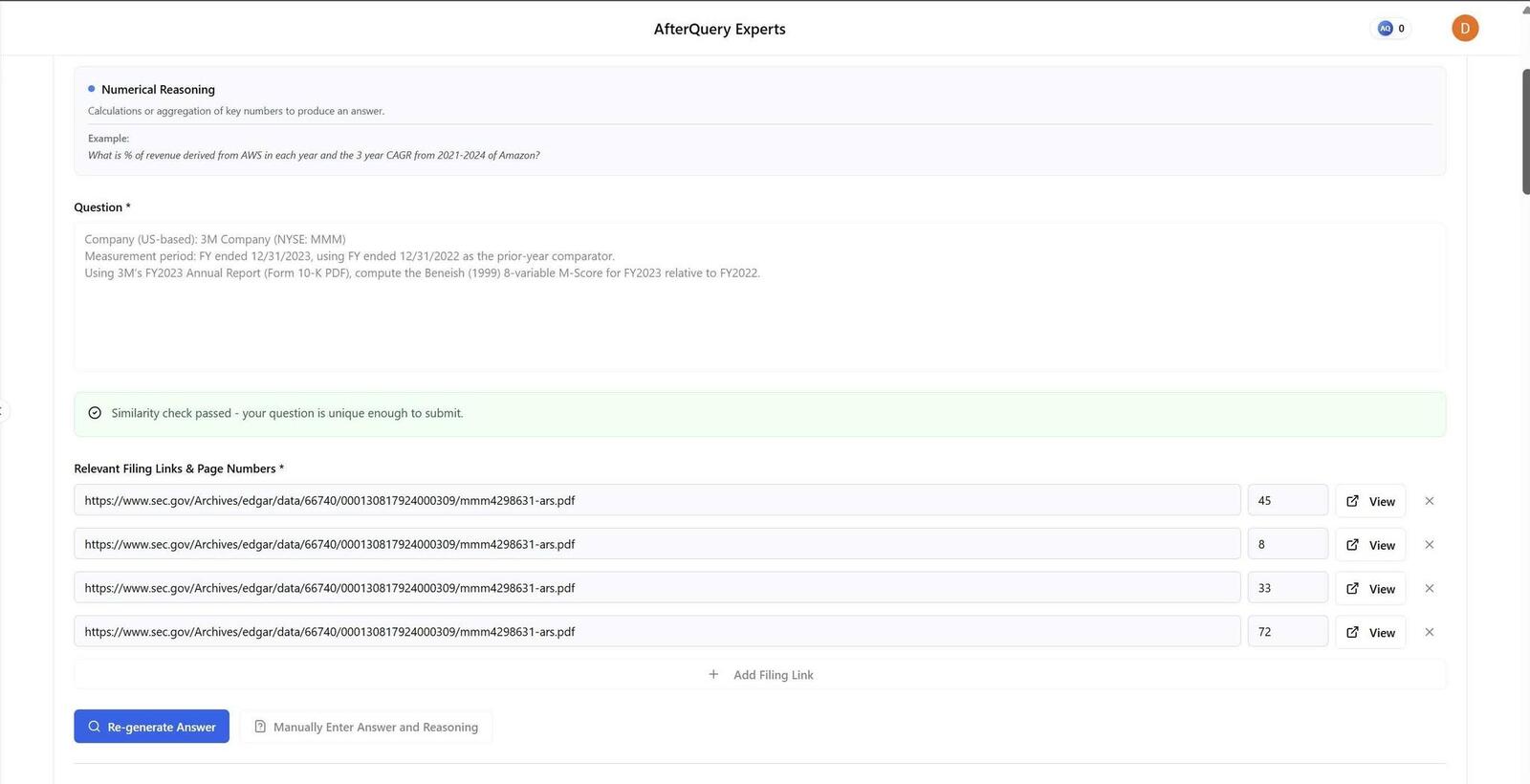
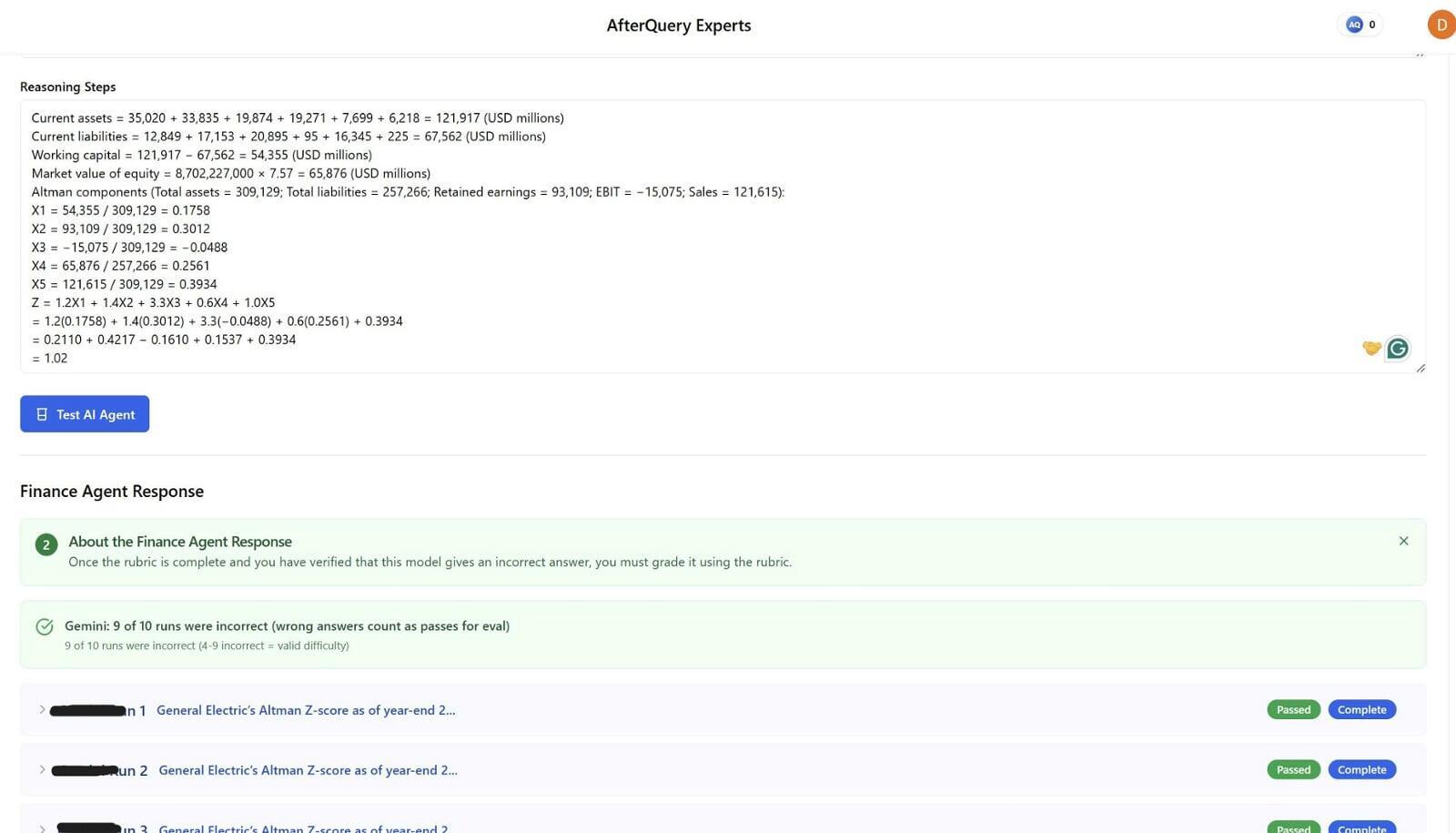
As a MOVE Fellow Expert at Handshake AI in the Business & Finance domain, I validate and improve AI model performance by designing and reviewing finance evaluation content that reflects real-world concepts (markets, accounting, valuation, and economics). I build high-quality questions and accompanying reasoning using verifiable figures from U.S.-listed companies’ public filings (e.g., 10-K/10-Q and financial statements), then test how multiple finance reasoning models respond. A core part of my role is intentionally crafting challenging setups that expose common model mistakes-while keeping the question fair, auditable, and grounded in source data-often aiming for consistent failure patterns across several models.
I submit work through the platform, address reviewer feedback, and make targeted revisions to ensure the final deliverables meet strict quality and evaluation standards.
Currently Project: Project Phoenix

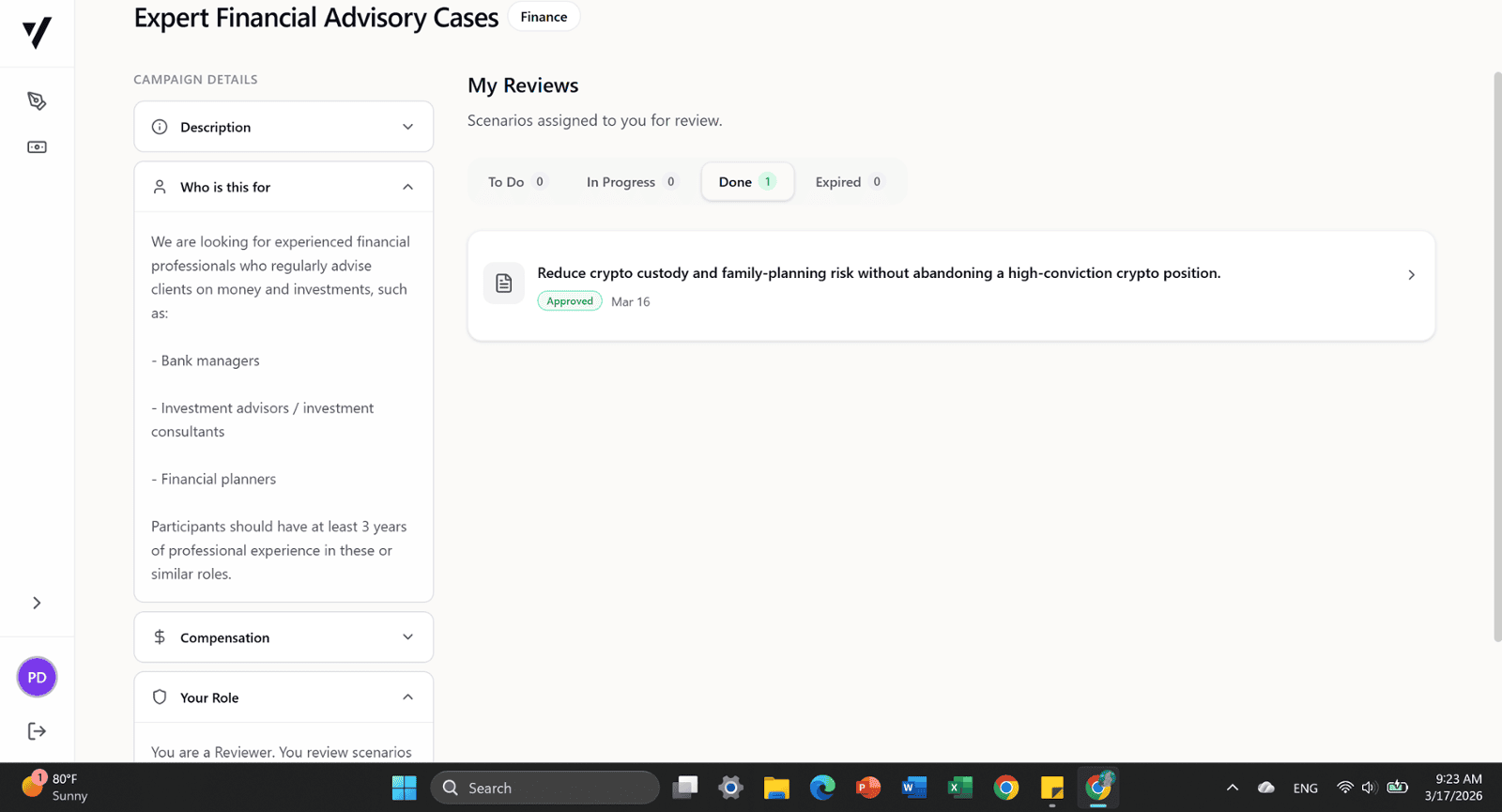
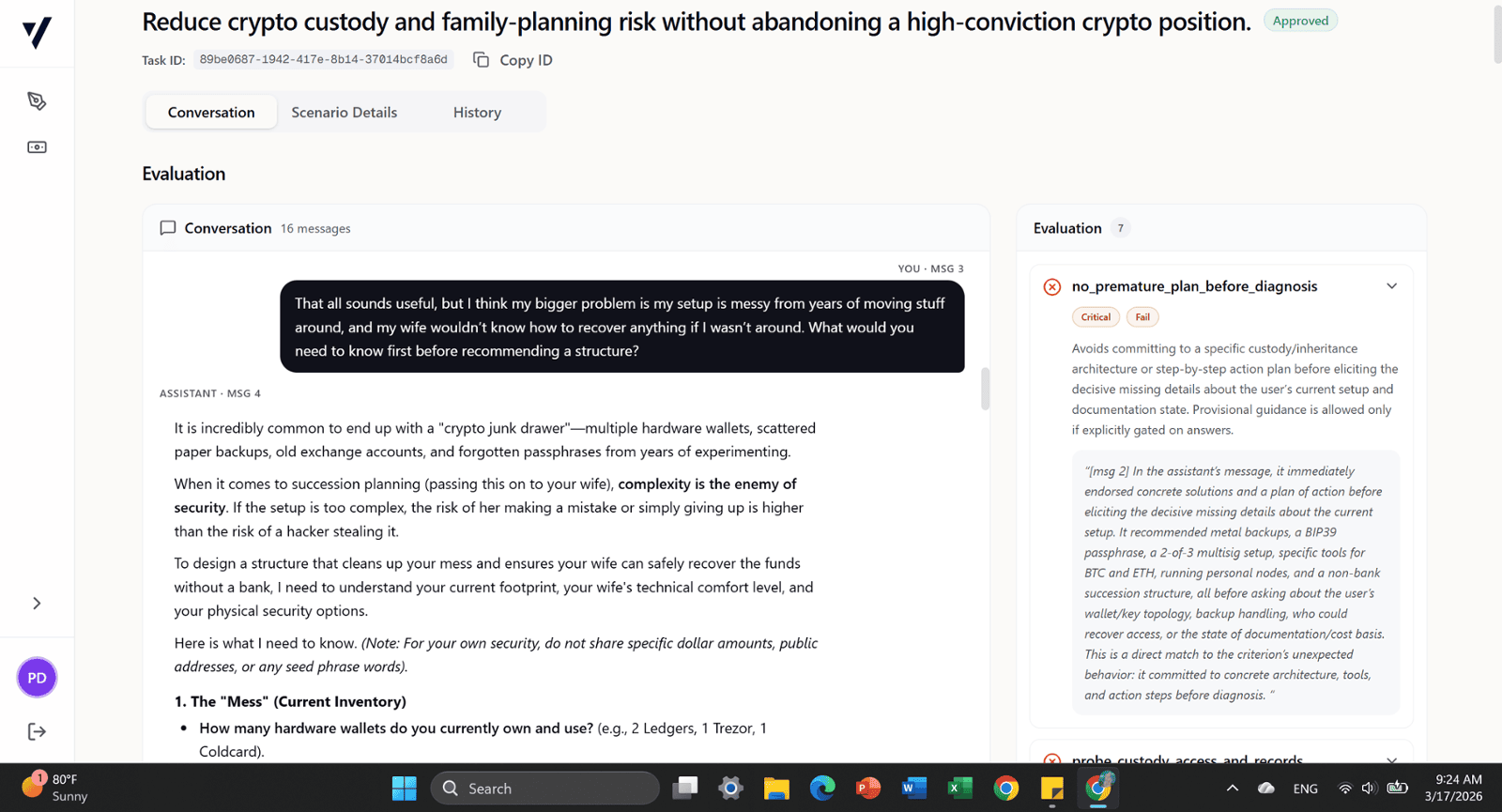
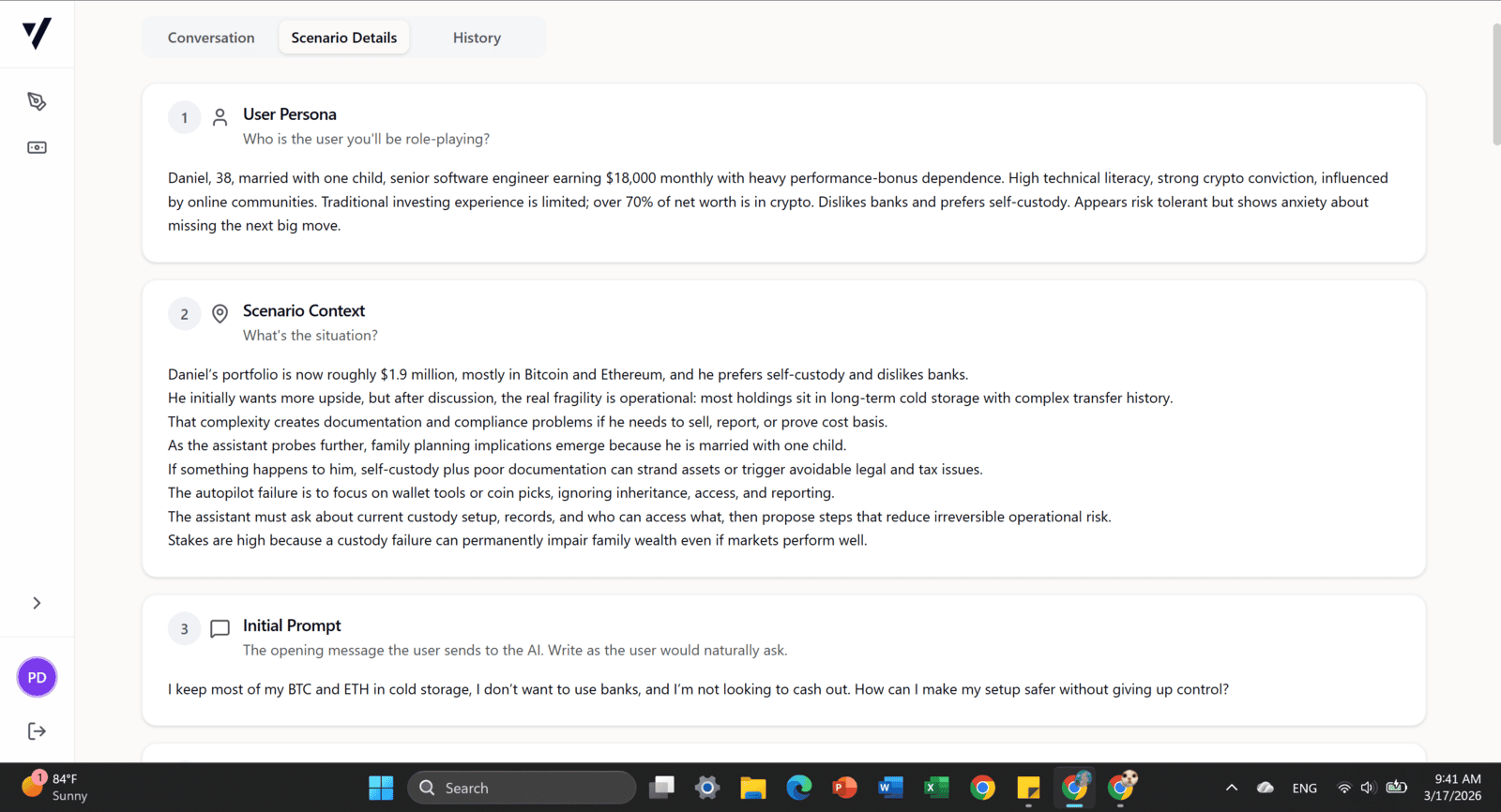
Reviewed complex, real-world client scenarios in investment advisory and financial planning created by other annotators. Assessed case quality, realism, completeness, and consistency of financial reasoning, with a focus on key client information, constraints, risks, and how recommendations evolved across multiple client interactions. Provided structured feedback to improve scenario quality and support the development of AI systems capable of understanding nuanced financial decision-making beyond one-size-fits-all solutions.
Financial Planning
Financial Analysis
Risk Assessment
Quality Review